Herkese merhaba,
Bu yazımda ML tahmin modellerine Neural Network ile devam edeceğim. Eğer okumadıysanız dizinin ilk iki yazısı Korelasyon ve Linear Regression‘u okumanızı tavsiye ederim.
Neural network aslında kabaca multiple input linear regresyon fonksiyonunda ibarettir. Linear regresyonla arasındaki tek fark, fonksiyonun çıktısının bir activation function (etkinleştirme fonksiyonu) ‘dan geçmesidir. Activation fonksiyonuna ihtiyaç duyuyoruz çünkü regresyon fonksiyonu doğrusalken activation fonksiyonları doğrusal değil genelde s şeklindedir. Dolayısıyla çok girdili doğrusal regresyon fonksiyonu karmaşık (yada doğrusal olmayan) bu fonksiyonlar ile öğrenebilme ve derinleşebilme yeteneği kazanıyor. Yani doğrusal fonksiyona doğrusal olmayan activation fonksiyonu ile networkün daha karmaşık fonksiyonları öğrenebilmesi sağlanıyor.
En yaygın kullanılan activation fonksiyonları: Sigmoid (Logistic) function ve tanh‘dir.
Sigmoid Fonksiyonu: çıktıları 0 ile +1 arasındadır.
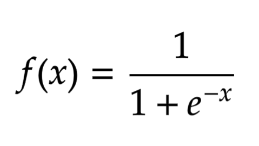
Tanh fonksiyonu: çıktıları -1 ile +1 arasındadır.
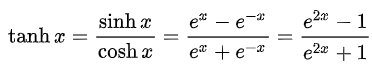
İki fonksiyonunda inputu tek x’dir. Ayrıca iki fonksiyonda da Euler (e=2,71) sayısının olduğuna dikkat edin. Euler aslında bir sıkıştırma fonksiyonudur ve ±∞ arasındaki tüm değerleri girdi kabul ederek önceden tanımlanmış bir aralığa sıkıştırır.
Activation fonksiyon olarak hangi fonksiyonu kullanacağınız çıktınızın alacağı değeri etkiler. Bu sebeple doğru fonksiyonu seçebilmek önemli.
Doğrusal regresyonda her girdi bir ağırlıkla ![]() çarpılır ve çarpım sonucu toplanır. Neural networkde buna ek olarak sonuca activation fonksiyonu uygulanır ve böylece doğrusallıktan çıkılır. Aşağıda bağlı bir neural network topolojisi gösterilmekte;
çarpılır ve çarpım sonucu toplanır. Neural networkde buna ek olarak sonuca activation fonksiyonu uygulanır ve böylece doğrusallıktan çıkılır. Aşağıda bağlı bir neural network topolojisi gösterilmekte;
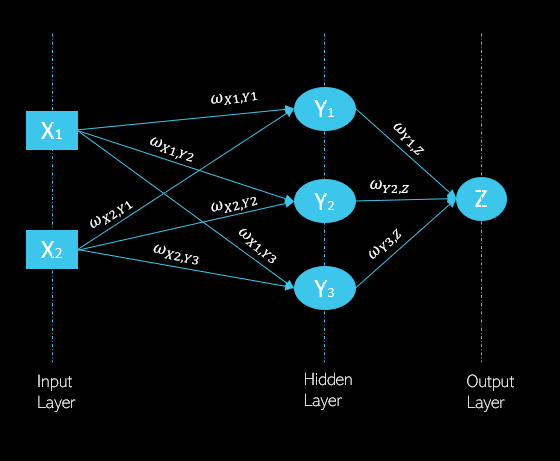
Herbir ağ üç kısımdan oluşur: input (girdi) katmanı, hidden (saklı) katman ve output (çıktı) katmanı. Herbir katman bir sonraki katmanı beslediği için bu bir feed forward (ileri beslemeli) bir ağdır. Yani X1’in activation fonksiyon uygulanmış çıktısı Y1 nöronunun girdisidir. Wx1,Y1 tam olarak X1 nöronundan gelen çıktının Y1 nöronuna girdi olarak geçtiğini ifade eder. Y1 nöronunun çıktısı da Z nöronunun girdisidir.
Diyelim ki yukarıdaki ağa tanh activation fonksiyonu uygulanacak;
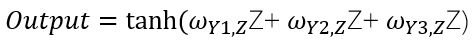
Gelelim neural network’ün eğitilmesine;
Bir neural networkü doğru ağırlıkları (yani doğru ağ banğlantılarını) bulmak için eğitiriz. Bu sebeple nöronlara gelen bağlantılardaki ağırlıkları güncellemek gerekir, bunun için de kurallar oluşturulur. Oluşturulacak olan bu kurallar hangi activation fonksiyonu kullandığımıza bağlı olarak değişir çünkü aslında activation fonksiyon kuralın türetilmesinde kullanılacak olan türevi etkiler. Ağırlık güncelleme kuralları da şu şekilde çalışır;
- Hata = 0 ise ağırlıklara dokunulmaz
- Hata > 0 ise inputun pozitif olduğu bağlarda ağırlık arttırılma, girdinin negatif olduğu bağlarda ağırlık azaltılmalı
- Hata < 0 ise girdiğin pozitif olduğu bağlardaki ağırlık azaltılmalı ve negatif bağlardaki ağırlık arttırılmalı
Neural networkün train edilmesi yani bağlantı ağırlıklarının hatalarına göre belirlenen kurala göre güncellenmesinde Backpropagation algoritması kullanılır. Bu algoritma ağdaki herbir nöron için herbir ağırlığa göre ağdaki hatanın türevini alarak hesaplar. Adım adım bakalım backpropagation algoritması nasıl çalışıyor.
- Çıktı katmanındaki nöronlar için hatayı hesaplar ve activation fonksiyonuna bağlı olarak ağırlık güncelleme kuralını çıktı nöronuna gelen ağırlıklara uygular.
- Böylece bir nöronda kullanılan hatayı, o nörona bağlanmış bir önceki katmandaki nöronların bağlantı ağırlıklarına paylaştırır.
- Katman katman geriye gidilerek ağın toplam hatası hesaplanır ve nöronlara giden bağlantılardaki ağırlıkları güncellemek için hata toplamının sonucu kullanılır.
Input ve hidden layer arasındaki tüm ağırlıklar güncellenene kadar bu süreç devam eder.
Peki hidden layer sayısını arttırrısak ne olur? Bir sonraki postta
